Mark, apparently, "volunteered" me to give a lightning talk last night over a dinner that I wasn't at, so apologies in advance if I run short or long.
Something that comes up frequently in our work on the TAG is the relationship between extensibility as a principle and how it relates to specific features we want in the web platform. To get anywhere in these debates, I think it's worth zooming out a bit.
The web has a strange origin story: we didn't build our way up from assembler and C, and the notion of moving words around memory is so far from the level of abstraction that HTML, JavaScript, and CSS provide that you can barely see them from there. Even VBScript, perhaps the most relevant contemporary, had a story for how that layering worked. The web, for decades, managed to do without.
Extensibility, then, has been an effective tool in the modern era for trying to understand the hidden linkages between the strange fauna and flora of this alien world. We can almost always get somewhere by asking dumb questions like "so, how does this thing relate to that other thing over there?". We nearly always turn up some missing primitive that we can catalog and reuse on our shared exploration.
But I'd submit that Extensibility is a tool in the same sense as Standards: it's possible to drive yourself mad with them if you lose track of the goal. Despite our setting today, this isn't academic. We're doing it all for a reason, and that reason needs to be a goal we share.
I can't set goals for you, but I can tell you what mine are and ask you to join me in them. My specific goal, then, is to improve the rate of progress on the web for the benefit of users and developers, in that order.
Put another way, I want to ensure the web is the platform developers invest in first and most, and that they do so because it's the easiest, best way to deliver great experiences.
With that in mind, it's easier to be kind to proposals that come to the TAG for high-level features, particularly if they're forging new ground or opening up new fundamental capabilities that the web didn't have but that will enrich user's experiences by improving developer's options.
Extensibility and Standards are incredibly useful tools but they make crummy religions.
There will be new features that aren't extensible by default. That's OK. Not ideal, but OK and, sometimes, unavoidable. What is avoidable is leaving the web's features sealed shut, never asking the questions about how things relate; never connecting the dots.
That would be a damned shame. I'm grateful the TAG has joined some of us insurrectionists in asking these questions, but we've got a long way to go. And my hope as we go there together is that we don't mistake the means for the goals.
This post is about vendor prefixes, why they didn’t work, and why it's toxic not to be able to launch experimental features. Also, what to do about it.
Recall that in 2012, Google, Apple, Blackberry, and a host of other vendors were all shipping browsers based on a single CSS engine (WebKit) without changing the -webkit- prefixes to be vendor-specific; e.g. -cr-, -apple-, or -bb-. As a result many experimental features experienced premature compatibility.Developers could get the benefits of broad feature support without a corresponding standard. This backed non-WebKit-based browsers into a terrible choice: "camp" on the other vendor’s prefixed behavior to render content correctly or suffer a loss of user and developer loyalty.
This illustrates what happens when experiments inadvertently become critical infrastructure. It has happened before. Over, and over, and overagain.
Prefixes were supposed to allow experimentation while discouraging misuse, but in practice they don’t. Prefixes "look" ugly and the thought was that ugliness — combined with an aversion to proprietary gunk by web developers — would cause sites to cease using them once standards are in place and browsers implement. But that’s not what happens.
Useful features that live a long time in the "experimental" phase tend to get “burned in”, particularly if the browsers supporting them are widely used. Breaking existing content is the third rail for browsers; all of their product instincts and incentives keep them from doing it, even if the breakage comes from retracting proprietary features. This means that many prefixed properties continue to work long after standard versions are added. Likewise, sites and pages that work with prefixes are all-too-easy for web developers to write and abandon. It’s unsettling to remove a prefix when you might break a user with an old browser. Maintenance of both sites and browsers rarely subtracts, but the theory of prefixes hinges on subtraction.
Everyone who uses prefixes, both browser engineers and web developers, start down the path thinking they’ll stop at some point. But for predictable reasons, that isn’t what happens. Good intentions are not an effective prophylactic. Not for web developers or browser makers (to say nothing of amorous teens).
This situation is the natural consequence of platform and developer time-scales that are out of sync. Browsers move more slowly than sites (at the micro scale), but sites must contend with huge browser diversity and are therefore much more conservative about removing "working" code than browser engineers expected.
Now What?
Years after Prefixpocalypse, everyone who works on a browser understands that prefixes haven’t succeeded in minimizing harm, yet vendors proudly announce new prefixed features and developers blithely (ab)use them. Clearly, a need for new features trumps interoperability and pollution concerns. This is natural and, perhaps even healthy. A static web, one which doesn’t do more to make lives better is one that doesn’t deserve to thrive and grow. In technology as in life there is no stasis, only various speeds of growth or decay.
Browsers could stop prefix pollution by simply vowing not to add features. This neatly analyses the problem (some experiments don’t work out, and some get out of hand) and proposes a solution (no experimentation), but as H.L. Mencken famously wrote:
…there is always a well-known solution to every human problem — neat, plausible, and wrong.
We have already run a natural experiment in this area. At the low point after the first browser war, Microsoft (temporarily) shrink from the challenge of building the web into a platform. Meanwhile IE 6’s momentum assured its place as the boat-anchor-browser. Between 2002 and 2006, the web (roughly) didn’t add any new features. Was that better? Not hardly. I’m glad to be done with 9-table-cell image hacks to accomplish rounded corners. Not all change is progress, but without change there is no progress.
"One does not simply ship no new features for a year and remain competitive"
The web does need new features, and we’d like good versions of them — fewer document.alls, WebSQLs and AppCaches, thanks.
We know from experience developing software of all kinds that more iteration yields better results. Experimentation, chances to learn, and opportunities to try alternatives are what separate good ideas from great products. Members of the Google Gears team report they considered building something like Service Workers. Instead they built an AppCache style system which didn’t work in all the ways AppCache didn’t work (which they couldn’t have known at the time). It shouldn’t have taken 6+ years to course-correct. We need to be able to experiment and iterate. Now that we understand the problems with prefixes, we need another mechanism.
Experiments That Stay Experiments
Prefixpocalypse happened because experiments escaped the lab. Wide-scale use of experimental properties isn’t healthy. Because prefixed properties were available to any site (no matter how large), it was straightforward for the killer combination of broad browser support and major site usage to ensure that compatibility would work against ever ending the experiment. The key to doing better, then, is to limit the size of the experimental population.
The way prefixes were run was like making a new drug available over the counter as soon as a promising early trial was conducted, skipping animal, human, and large-scale clinical trials. Of course that would be ludicrous; "first do no harm" requires starting with a small population, showing efficacy, gathering data about side-effects, and iterating.
The missing ingredient has been the ability to limit the experimental population. Experiments can run for fixed duration without fear of breaking the web if we can be sure that they never imperiled the whole web in the first place. Short duration and small, committed test populations allow for more iteration which should, in the end, lead to better features. Web developer feedback needs to be the most important voice in the standards process, and we’ll never get there until there’s more ability for web developers to participate in feature evolution.
Experimental outcomes are ammo for the standards development process; in the best-case they can provide good evidence that a feature is both needed and well-designed.
Putting evidence at the core of web feature and standards development is a 180° change from the current M.O., but one we sorely need.
So how do we get there?
Some mechanisms I’ve thought through and rejected (with reasons):
"Just have users flip things in about:flags"
This has several persistent downsides: first, it doesn’t limit the size of the experimental population. If every site encourages users to flip a particular flag, odds are enough users will do so to set usage above a red-line threshold.
"Enable it by default on your Beta/Dev channel browser"
Like the flag-flipping mechanism, it puts a burden on users which is exactly backward. Experiments will get better feedback when developers can work with features without the friction of asking users to switch browser.
The Chrome Team has been thinking about this problem for the past several years, including conversations with other vendors, and those ideas have congealed into a few interlocking mechanisms that haven’t been rejected:
Developer registration & usage keys.
A large part of the reason it’s difficult to change developer behavior about use of experimental features is that it’s hard to find them! Who would you call to talk about use of some prefixed CSS thing on facebook.com? I don’t know either. Having an open communication channel is critical to learning how features are working (or not) in the real world. To that end, new experimental features will be tied to specific origins using keys vended by a developer program; sites supply the keys to the browser through header/meta tags, enabling the features dynamically. Registration for the program will probably require giving a (valid) email address and agreeing to answer survey questions about experimental features. Because of auto-self-destruct (see below), there’s less worry that these experiments will be abused to provide proprietary features to "preferred" origins. Public dashboards of running experiments and users will ensure transparency to this effect.
Global usage caps.
The Blink project generally uses a ~0.03% usage threshold to decide if it’s plausible to remove a feature. Experimenters might use our Use Counter infrastructure and RAPPOR to monitor use. Any feature that breaches this threshold can automatically close the experiment to new users and, if any individual user goes above ~0.01% (global) use, a config update can be pushed to throttle use on that site.
Feature auto-self-destruct.
Experimental features should be backed by a process that’s trying to learn. To enable this, we’re going to ensure that each version of an experimental feature auto-self-destructs, tentatively set at 12–18 weeks per experiment. New iterations which are designed to test some theory can be launched once an experiment has finished (but must have some API or semantic difference, preferably breaking). Sites that want to opt into the next experiment and were part of a previous group will be asked survey questions in the key-update process (which is probably going to be a requirement for access to future experimental versions). Experiments can overlap to provide continuity for end-users who are willing to move to the next-best-guess and provide feedback.
We’re also going to work to ensure that the surfaced APIs are done in a responsible way, including feature-detection where possible. These properties add up to a solution that gives us confidence that we can create Ctrl-Z for web features without damaging users or sites.
In discussions with our friends in the community and at other browser vendors we’ve thought through alternative ways to throttle or shrink the experimental population: randomness in API names, limiting APIs to postMessage style calling, or shortening experiment lifetimes. As Chrome is going first, we’ll be iterating on the experimental framework to try to strike the right balance that allows enough use to learn from but not so much that we inadvertently commit to an API. We'll also be sharing what we learn.
My hope is that other browsers implement similar programs and, as a corollary, cease use of prefixes. If they do, I can imagine many future areas for collaboration on developing and running these experiments. That said, it’s desirable to for different browsers to be trying different designs; we learn more through diversity than premature monoculture.
Moving faster and building better features don’t have to be in tension; we can do better. It’s time to try.
There's a post on the fetch() API by Ludovico Fischer doing the rounds. As a co-instigator for adding the API to the platform, it's always a curious thing to read commentary about an API you designed, but this one more than most. It brings together the epic slog that was the Promises design (which we also waded into in order to get Service Workers done and which will improve with await/async) with the in-process improvements that will come from Streams and it mixes it with a dollop of FUD, misunderstanding, and derision.
This sort of article is emblematic of a common misunderstanding. It expresses (at the end) a latent belief that there is some better alternative available for making progress on the web platform than to work feature-by-feature, compromise-by-compromise towards a better world. That because the first version of fetch() didn't have everything we want, it won't ever. That there was either some other way to get fetch() shipped or that there was a way to get cancellation through TC39 in '13. Or that subclassing is somehow illegitimate and "non-standard" (even though the subclass would clearly be part of the Fetch Standard).
These sorts of undirected, context-free critiques rely on snapshots of the current situation (particularly deficiencies thereof) to argue implicitly that someone must be to blame for the current situation not yet being as good as the future we imagine. To get there, one must apply skepticism about all future progress; "who knows when that'll be done!" or "yeah, fine, you shipped it but it isn't available in Browser X!!!".
They're hard to refute because they're both true and wrong. It's the prepper/end-of-the-world mentality applied to technological progress. Sure, the world could come to a grinding halt, society could disintegrate, and the things we're currently working on could never materialize. But, realistically, is that likely? The worst-case-scenario peddlers don't need to bother with that question. It's cheap and easy to "teach the controversy". The appearance of drama is its own reward.
Perhaps most infuriatingly, these sorts of cheap snapshots laced with FUD do real harm to the process of progress. They make it harder for the better things to actually appear because "controversy" can frequently become a self fulfilling prophesy; browser makers get cold feet for stupid reasons which can create negative feedback loops of indecision and foot-gazing. It won't prevent progress forever, but it sure can slow it down.
I'm disappointed in SitePoint for publishing the last few paragraphs in an otherwise brilliant article, but the good news is that it (probably) won't slow Cancellation or Streams down. They are composable additions to fetch() and Promises. We didn't block the initial versions on them because they are straightforward to add later and getting the first versions done required cuts. Both APIs were designed with extensions in mind, and the controversies are small. Being tactical is how we make progress happen, even if it isn't all at once. Those of us engaged in this struggle for progress are going to keep at it, one feature (and compromise) at a time.
It happens on the web from time to time that powerful technologies come to exist without the benefit of marketing departments or slick packaging. They linger and grow at the peripheries, becoming old-hat to a tiny group while remaining nearly invisible to everyone else. Until someone names them.
This may be the inevitable consequence of a standards-based process and unsynchronized browser releases. We couldn't keep a new feature secret if we wanted to, but that doesn't mean anyone will hear about it. XMLHTTPRequest was available broadly since IE 5 and in Gecko-based browsers from as early as 2000. "AJAX" happened 5 years later.
This eventual adding-up of new technologies changes how we build and deliver experiences. They succeed when bringing new capabilities while maintaining shared principles:
URLs and links as the core organizing system: if you can't link to it, it isn't part of the web
Markup and styling for accessibility, both to humans and search engines
UI Richness and system capabilities provided as additions to a functional core
Free to implement without permission or payment, which in practice means standards-based
Major evolutions of the web must be compatible with it culturally as well as technically.
Many platforms have attempted to make it possible to gain access to "exotic" capabilities while still allowing developers to build with the client-side technology of the web. In doing so they usually jettison one or more aspect of the shared value system. They aren't bad — many are technically brilliant — but they aren't of the web:
These are just the ones that spring to mind offhand. I'm sure there have been others; it's a popular idea. They frequently give up linkability in return for "appiness": to work offline, be on the home screen, access system APIs, and re-engage users they have required apps be packaged, distributed through stores, and downloaded entirely before being experienced.
Instead of clicking a link to access the content you're looking for, these systems make stores the mediators of applications which in turn mediate and facilitate discovery for content. The hybridzation process generates applications which can no longer live in or with the assumptions of the web. How does one deploy to all of these stores all at once? Can one still keep a fast iteration pace? How does the need to package everything up-front change your assumptions and infrastructure? How does search indexing work? It's a deep tradeoff that pits fast-iteration and linkability against offline and store discovery.
Escaping the Tab: Progressive, Not Hybrid
But there is now another way. An evolution has taken place in browsers.
Over dinner last night, Frances and I enumerated the attributes of this new class of applications:
Linkable: meaning they're zero-friction, zero-install, and easy to share. The social power of URLsmatters.
These apps aren't packaged and deployed through stores, they're just websites that took all the right vitamins. They keep the web's ask-when-you-need-it permission model and add in new capabilities like being top-level in your task switcher, on your home screen, and in your notification tray. Users don't have to make a heavyweight choice up-front and don't implicitly sign up for something dangerous just by clicking on a link. Sites that want to send you notifications or be on your home screen have to earn that right over time as you use them more and more. They progressively become "apps".
Critically, these apps can deliver an even better user experience than traditional web apps. Because it's also possible to build this performance in as progressive enhancement, the tangible improvements make it worth building this way regardless of "appy" intent.
Frances called them "Progressive Open Web Apps" and we both came around to just "Progressive Apps". They existed before, but now they have a name.
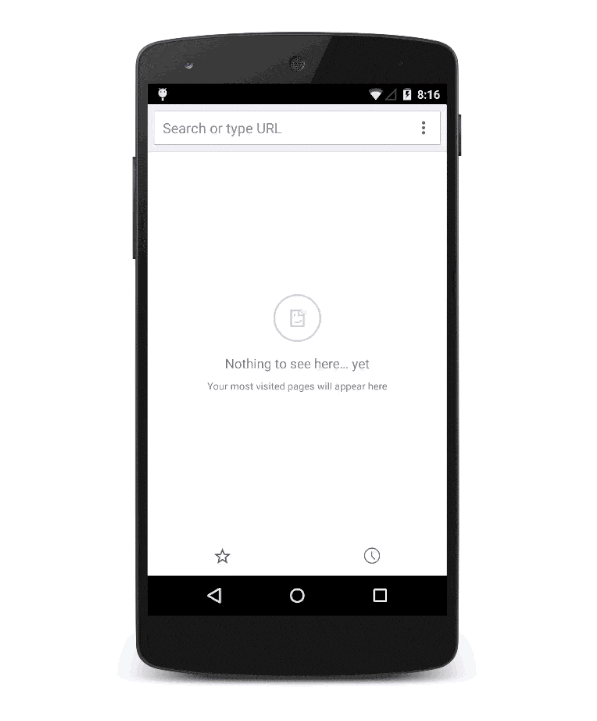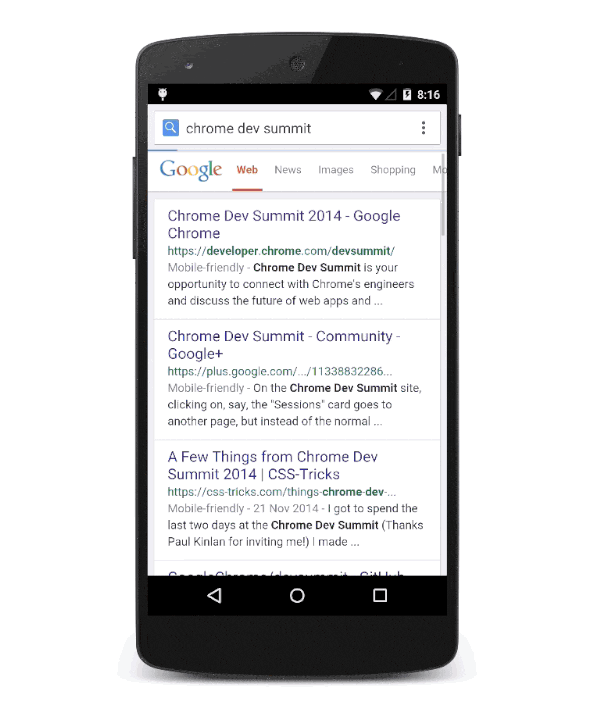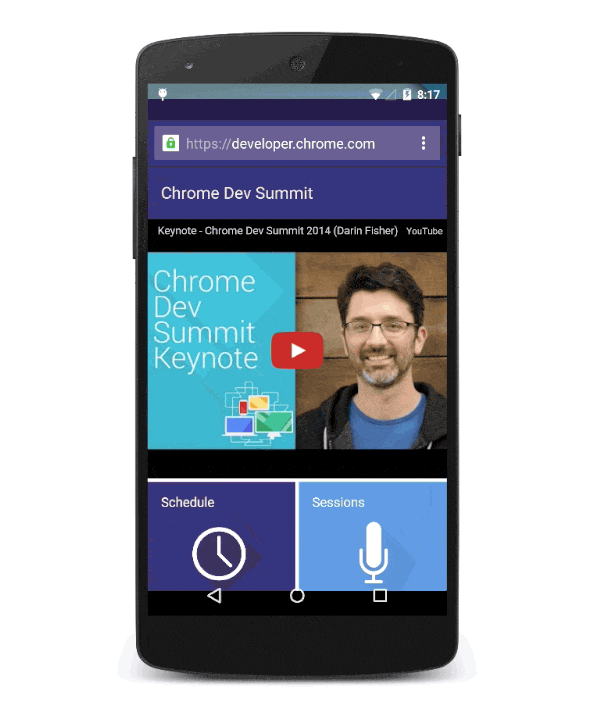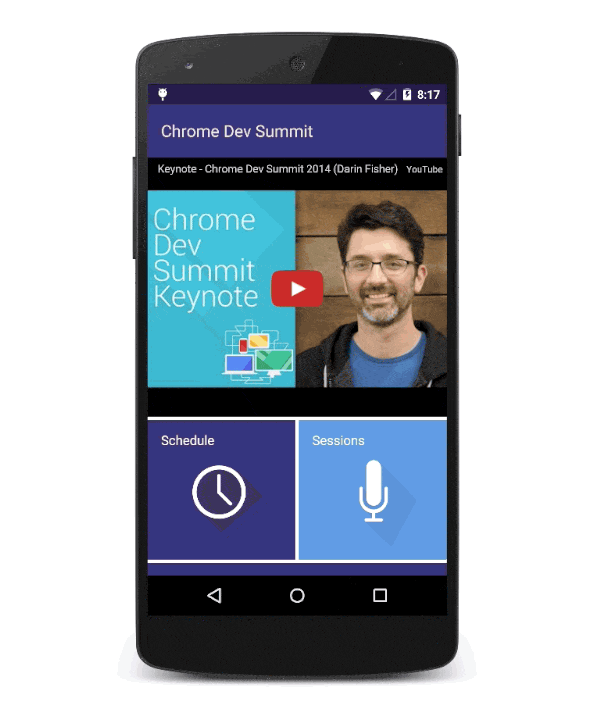
The site begins life as a regular tab. It doesn't have super-powers, but it is built using Progressive App features including TLS, Service Workers, Manifests, and Responsive Design.
The second (or third or fourth) time one visits the site -- roughly at the point where the browser it sure it's something you use frequently -- a prompt is shown by the browser (populated from the Manifest details)
Users can decide to keep apps to the home screen or app launcher
When launched from the home screen, these apps blend into their environment; they're top-level, full-screen, and work offline. Of course, they worked offline after step 1, but now the implicit contract of "appyness" makes that clear.
Progressive Web App installation flow for Chrome Dev Summit.
Here's the same flow on Flipboard today:
Progressive Apps are web apps, they begin life in a tab. Here we see flipboard.com in Chrome for Android with regular tab treatment.When users engage with Progressive Web Apps enough, browsers offer prompts that ask users if they want to keep them. To avoid spaminess, this doesn't happen on the first load.If the user accepts, the user's flow isn't interrupted.The app shortcut appears on the homescreen or launcher of the OS.When launched, Progressive Web Apps can choose to be full-screen.Progressive Web Apps are top-level activities in the OS's application switcher.
The Future
Today's web development tools and practices don't yet naturally support Progressive Apps, although many frameworks and services are close enough to be usable for making Progressive Apps. In particular, client-side frameworks that have server-rendering as an option work well with the model of second-load client-side routing that Progressive Apps naturally adopt as a consequence of implementing robust offline experiences.
This is an area where thoughtful application design and construction will give early movers a major advantage. Full Progressive App support will distinguish engaging, immersive experiences on the web from the "legacy web". Progressive App design offers us a way to build better experiences across devices and contexts within a single codebase but it's going to require a deep shift in our understanding and tools.
Building immersive apps using web technology no longer requires giving up the web itself. Progressive Apps are our ticket out of the tab, if only we reach for it.
IF YOU DO NOT RUN A SITE THAT HOSTS UNTRUSTED/USER-PROVIDED FILES OVER SSL/TLS, YOU CAN STOP READING NOW
This post describes the potential amplification of existing risks that Service Workers bring for multi-user origins where the origin may not fully trust the content or, in which, users should not be able to modify each other's content.
Sites hosting multiple-user content in separate directories, e.g. /~alice/index.html and /~bob/index.html, are not exposed to new risks by Service Workers. See below for details.
Sites which host content from many users on the same origin at the same level of path separation (e.g. https://example.com/alice.html and https://example.com/bob.html) may need to take precaution to disable Service Workers. These sites already rely on extraordinary cooperation between actors and are likely to find their security assumptions astonished by future changes to browsers.
Like AppCache, Service Workers are available without user prompts and enable developers to create meaningful offline experiences for web sites. They are, however, strictly more powerful than AppCache.
To mitigate the risks associated with request interception, Service Workers are only available to use under the following restrictions:
Service Workers are restricted to secure origins. E.g., http://acme.com/ can never have a Service Worker installed, whereas https://acme.com can. If you do not serve over SSL/TLS, service workers do not impact your site.
Service Worker scripts must be hosted at the same origin. E.g., https://acme.com/index.html can only register a Service Worker script if that script is also hosted at https://acme.com. Scripts included by the root Service Worker via importScripts() may come from other origins, but the root script itself cannot be registered against another origin. Redirects are also treated as errors for the purposes of SW script fetching to ensure that attackers cannot turn transient ownership into long-term control.
Service Workers are restricted by the path of the Service Worker script unless the Service-Worker-Scope: ... header is set.
Service Workers intercept requests for documents and their sub-resources. These documents are married to SW's based on longest-prefix-match of the path component of the script which is registered with the scopes.
For example, if https://acme.com/thinger/index.com registers a SW hosted at https://acme.com/thinger/sw.js, it cannot by default intercept requests for https://acme.com/index.html
This example may, however, respond for more-specific document requests like https://acme.com/thinger/blargity/index.html.
If the script is instead located at https://acme.com/sw.js, the registration will allow interception for all navigations at https://acme.com/.
This means that sites hosting multiple-user content in separated directories, e.g. /~alice/ and /~bob/, are not exposed to new risks by Service Workers.
Sites which host multiple user's content in the same directories may wish to consider disabling Service Workers (see below).
Servers can break this restriction on allowed scope by sending a Service-Worker-Scope: ... header, where the value of the header is the allowed path (e.g., /). This feature will not arrive for Chrome until version 41 (6 weeks after the original release which adds support for Service Workers).
Service Worker scripts must be served with valid JavaScript mime types, e.g. text/javascript. Resources served with marginal Content-Type values, e.g. text/plain, will NOT be respected as valid Service Worker scripts.
If you run a site which hosts untrusted third-party content on a single origin over SSL/TLS, you should ensure that you:
Disable Service Workers at your origin by blocking requests which include the Service-Worker: script header. This is easily accomplished using global server configuration (e.g. httpd.conf directives).
If you wish to allow Service Workers, Begin auditing use of Service Workers on your origin as requests which include Service-Worker: script may indicate other problems with content hosting (e.g., if you do not mean to be hosting active HTML content but are doing so incidentally).
Move to a sub-domain-per-user model as soon as possible, e.g. https://alice.example.com instead of https://example.com/~alice. The browser-enforced same-origin model is fundamentally incompatible with serving content from multiple entities at the same origin. For instance, sites which can run on the same origin are susceptible to easy-to-make mixups with Cookie paths and storage poisoning attacks via Local Storage, WebSQL, IndexedDB, the Filesystem API, etc. The browser's model for how to separate principals relies almost exclusively on origins and we strongly recommend that you separate users by sub-domain (which is a different origin) so that future changes to browsers do not cause harmful interactions with your hosting setup.